
Obsirag
Un cerveau qui apprend de tes notes Obsidian : RAG local, génération d'insights automatiques, enrichissement web sur sources fiables. Python · ChromaDB · Ollama.
ObsiRAG
ObsiRAG transforme votre coffre Obsidian en une base de connaissances interrogeable par les agents IA — via un moteur RAG local et un serveur MCP natif.
Posez des questions en langage naturel sur l'intégralité de vos notes. Connectez Claude, Cursor ou tout agent compatible MCP à votre coffre en quelques lignes de configuration.
Deux usages, une seule installation
Recherche RAG — interroger votre coffre en langage naturel
Posez n'importe quelle question ; ObsiRAG retrouve les passages pertinents dans vos notes et génère une réponse ancrée dans votre propre savoir.
- "Quelles sont mes dernières notes ? Fais une synthèse de cette semaine."
- "Comment la lumière bleue affecte-t-elle mon repos ?" → retrouve la note sur les écrans et le sommeil, même si ces mots exacts n'y apparaissent pas
- "Qu'est-ce que j'ai appris ce mois-ci sur l'IA ?"
Le coffre reste en lecture seule — ObsiRAG ne modifie jamais vos notes Obsidian existantes. Tout fonctionne 100% en local : vos données ne quittent jamais votre machine.
Intégration MCP — connecter vos agents IA à Obsidian
ObsiRAG expose un serveur MCP (Model Context Protocol) qui permet à Claude Desktop, Cursor, Copilot ou tout agent compatible d'interroger directement votre coffre Obsidian.
L'agent peut rechercher des notes, lire leur contenu, naviguer dans le graphe de connaissances, poser des questions RAG et parcourir vos notes par date — tout cela sans quitter sa fenêtre de travail. Obsidian devient un outil de mémoire longue terme pour vos workflows IA.
Serveur MCP — architecture HTTP (SSE)
NOUVEAU : ObsiRAG expose un serveur MCP natif via HTTP (SSE) directement depuis FastAPI, sans subprocess stdio. Cela signifie :
- ✅ Pas de timeout initialize — réponse < 100ms
- ✅ Process persistant — lancé une fois avec le backend
- ✅ Logs propres — zéro pollution stdout
- ✅ Auth Bearer token — sécurité intégrée
- ✅ Scalable — support clients multiples concurrent
Quick-start
1. Configuration .env (optionnel — auth)
# Générer un token:
# openssl rand -hex 32 | sed 's/^/sk-obsirag-/'
MCP_AUTH_TOKEN=sk-obsirag-a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6
2. Démarrer
./start.sh
# MCP HTTP disponible sur: http://localhost:8081/mcp
2bis. Vérifier MCP rapidement
python scripts/mcp_smoke_test.py --base-url http://localhost:8081
# Avec auth:
python scripts/mcp_smoke_test.py \
--base-url http://localhost:8081 \
--auth-token "sk-obsirag-..."
3. Configurer Claude Desktop
Fichier: ~/Library/Application\ Support/Claude/claude_desktop_config.json
{
"mcpServers": {
"obsirag": {
"url": "http://localhost:8081/mcp",
"auth": {
"type": "bearer",
"token": "sk-obsirag-a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6"
}
}
}
}
Puis relancer Claude :
killall Claude
open -a Claude
Outils MCP exposés
| Outil | Description |
|---|---|
obsirag_ask_rag | Recherche RAG principale. Pose une question sur le coffre via Ollama. Bascule automatiquement sur Euria + recherche web si le coffre ne suffit pas. |
obsirag_search_notes | Recherche des notes par titre ou chemin relatif dans le coffre indexé. |
obsirag_search_notes_semantic | Recherche vectorielle (embedding). |
obsirag_get_note | Retourne le contenu Markdown complet et les métadonnées d'une note connue. |
obsirag_browse_notes_by_date | Liste les notes triées par date de modification décroissante. |
obsirag_get_graph_subgraph | Explore le graphe de connaissances autour d'une note. |
obsirag_get_entity_stats | Statistiques sur les entités NER détectées. |
obsirag_get_graph_filters | Options disponibles pour filtrer le graphe. |
obsirag_get_system_status | État du runtime, indexation, composants actifs. |
obsirag_conversation_start | Démarre une conversation d'investigation persistée. |
obsirag_conversation_continue | Ajoute un tour à une investigation en cours. |
obsirag_conversation_finalize | Clôt une investigation et sauvegarde la synthèse. |
obsirag_list_folder | Énumération des dossiers et fichiers dans le coffre. |
Documentation complète
Backward compatibility
Le transport stdio legacy est conservé pour usages pre-HTTP :
# Mode historique (déprécié)
python -m src.mcp.server
Mais la production utilise HTTP (./start.sh).
Comment fonctionne la recherche sémantique
1. Découpage en chunks
Chaque note est découpée en morceaux (chunks) d'environ 300 mots avec chevauchement, en respectant la structure (## Titre, paragraphes). Chaque chunk hérite des métadonnées de la note (titre, tags, dates, wikilinks, entités NER…).
2. Vectorisation (embedding)
Chaque chunk est transformé en vecteur numérique par le modèle paraphrase-multilingual-MiniLM-L12-v2 (sentence-transformers, calcul CPU local, multilingue natif). Deux passages sémantiquement proches produisent des vecteurs proches — même sans mot en commun.
3. Stockage dans LanceDB
Les vecteurs sont stockés dans LanceDB (base vectorielle locale, fichiers dans data/lance/). L'indexation est incrémentale : seules les notes nouvelles ou modifiées sont retraitées.
4. Recherche à la requête
- La question est vectorisée
- LanceDB identifie les chunks les plus proches par similarité cosinus
- Ces chunks sont injectés comme contexte dans le prompt envoyé à Ollama
- Le modèle génère une réponse ancrée dans votre coffre, pas dans ses seules connaissances pré-entraînées
C'est ce mécanisme qui permet de retrouver une note sur "les effets des écrans sur le sommeil" en posant la question "comment la lumière bleue affecte-t-elle le repos ?" — sans que ces mots exacts apparaissent dans la note.
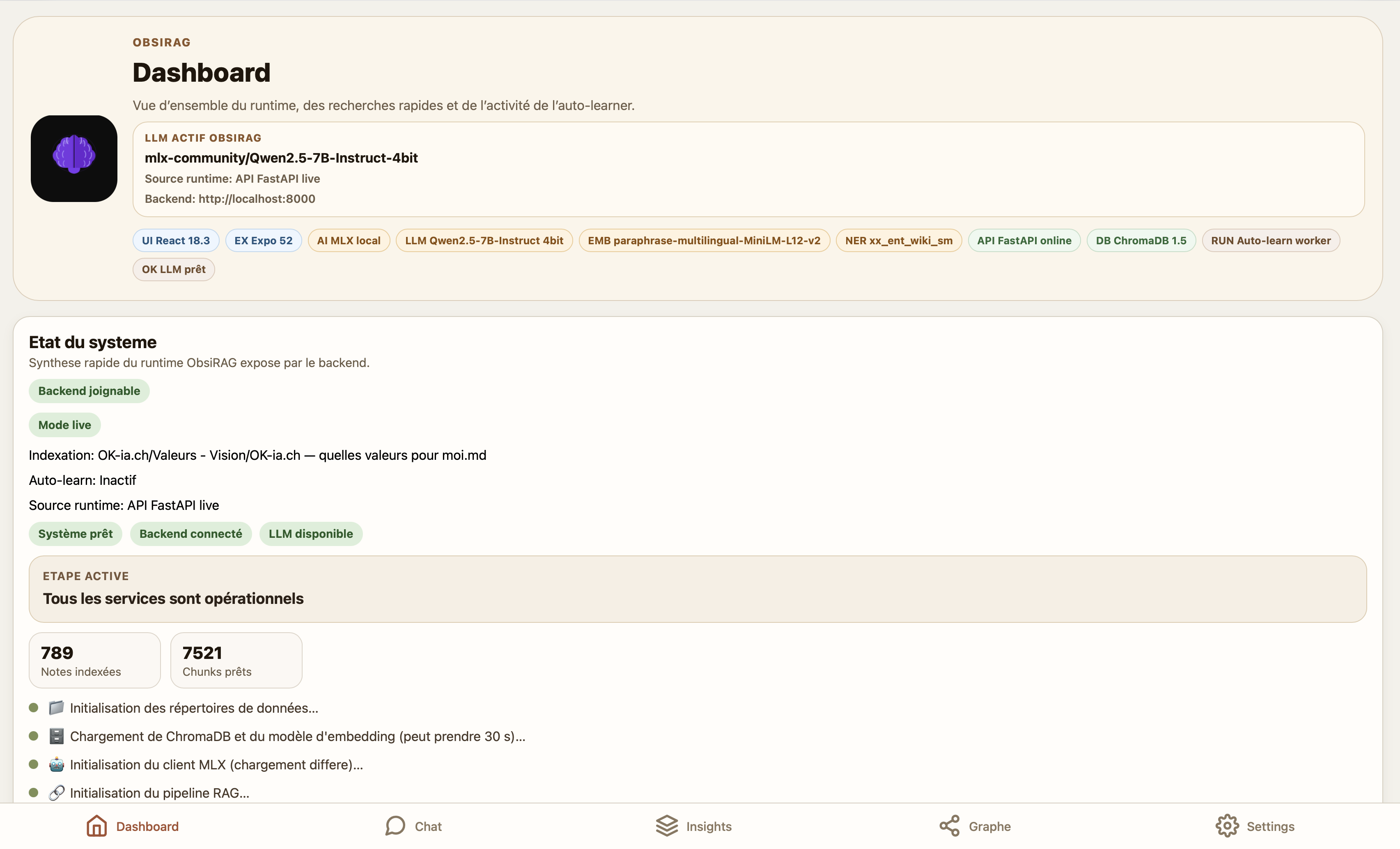
Aperçu visuel
Dashboard système
Chat RAG
Interface de conversation avec note principale, sources et provenance.

Graphe du cerveau
Exploration du coffre par connexions, synapses et filtrage.

Insight détaillé

Interface web
ObsiRAG expose une interface Expo React Native web sur le port 8080, avec :
- Chat RAG : conversation enrichie avec note principale, sources et provenance
- Graphe cerveau : visualisation interactive des connexions entre notes
- Insights & Synapses : consultation des artefacts générés automatiquement
- Conversations : historique des fils de discussion sauvegardés
- Réglages : configuration Ollama, Euria, feature toggles
Chat — comportement conversationnel
- Relances résolues dans le fil : "tu as plus de détail sur les objectifs" est rattaché automatiquement au sujet précédent
- Note principale : la note la plus dominante remonte en priorité dans le contexte
- Garde-fou anti hors-sujet : si aucun chunk fiable n'est trouvé, ObsiRAG répond "Cette information n'est pas dans ton coffre." plutôt que de laisser le modèle halluciner
- Diagrammes Mermaid : les blocs Mermaid s'ouvrent dans un viewer intégré
Fallback Euria + recherche web
Quand le coffre ne suffit pas, le backend bascule automatiquement sur Euria (Infomaniak, google/gemma-4-31B-it) avec recherche web DuckDuckGo. Le champ provider dans la réponse indique quel LLM a répondu (ollama ou euria+web).
Génération automatique d'artefacts
Insights
Un auto-learner tourne en arrière-plan et génère pour chaque note des questions perspicaces avec réponses RAG + web. Les insights sont sauvegardés dans obsirag/insights/YYYY-MM/ avec provenance et références citées — et deviennent eux-mêmes interrogeables dans le chat.
Synapses
Des connexions implicites entre notes sémantiquement proches (sans wikilink existant) sont détectées et sauvegardées dans obsirag/synapses/. Ces fichiers contiennent des wikilinks vers les deux notes sources, les enrichissant dans le graphe de connaissances.
Conversations d'investigation
Le chat expose un bouton 💾 Sauvegarder qui crée une note Markdown dans obsirag/conversations/YYYY-MM/ avec titre généré par le LLM. Ces notes sont indexées et interrogeables dans les cycles suivants.
Les artefacts générés sont exclus par défaut des résultats RAG et MCP (paramètre exclude_obsirag_generated), pour ne pas polluer les réponses avec du contenu généré.
Désactivés par défaut : la génération d'insights et de synapses est désactivée au premier démarrage. Activer depuis Réglages → Génération automatique.
Déploiement Docker
ObsiRAG tourne dans un container Docker unique géré par docker compose.
Démarrage rapide
# Configurer l'environnement
cp .env.example .env
# Éditer .env : VAULT_PATH, OLLAMA_BASE_URL, OLLAMA_CHAT_MODEL, API_KEY, etc.
# Créer le volume de données persistant
docker volume create obsirag-data
# Démarrer
docker compose up -d
L'interface web et l'API sont disponibles sur http://localhost:8080.
Commandes utiles
docker compose up -d # démarrer
docker compose up -d --build # rebuild + redémarrer (après un changement de code)
docker compose logs -f # logs API
docker exec obsirag tail -f /app/logs/worker.log # logs auto-learner
docker compose restart # redémarrer sans rebuild
docker compose down # arrêter
Architecture interne du container
- PID 1 : uvicorn (API FastAPI, port 8080)
- cron
@reboot: démarre le worker auto-learner (src.learning.worker) 10 secondes après le démarrage - cron
*/5: vérifie que le worker est vivant et le relance si nécessaire - Volume
obsirag-data: LanceDB + stats + état autolearn (persistant entre les redémarrages) - Bind mount coffre :
VAULT_PATHmonté en lecture/écriture dans/vault
Variables d'environnement clés
| Variable | Rôle |
|---|---|
VAULT_PATH | Chemin absolu vers le coffre Obsidian sur l'hôte |
OLLAMA_BASE_URL | URL du serveur Ollama (ex. http://host.docker.internal:11434) |
OLLAMA_CHAT_MODEL | Modèle de chat (ex. qwen2.5:7b) |
EURIA_API_KEY | Clé Euria/Infomaniak (optionnel — active le fallback cloud) |
API_KEY | Clé d'authentification de l'API ObsiRAG (optionnel) |
AUTOLEARN_ALLOW_BACKGROUND_LLM | true pour activer l'auto-learner (géré par cron dans Docker) |
Stack technique
| Composant | Technologie |
|---|---|
| Langage | Python 3.12 |
| Déploiement | Docker (multi-stage : Node 22 Alpine + Python 3.12 slim) |
| IA locale | Ollama (API compatible OpenAI) — qwen2.5:7b par défaut |
| IA cloud optionnel | Euria/Infomaniak — google/gemma-4-31B-it |
| Base vectorielle | LanceDB (fichiers locaux dans data/lance/) |
| Embeddings | sentence-transformers paraphrase-multilingual-MiniLM-L12-v2 (768 dim, CPU, multilingue) |
| Interface | Expo React Native web + FastAPI |
| Protocole agents | MCP HTTP (SSE) + stdio legacy |
| Graphe | NetworkX + Pyvis |
| Recherche web | DuckDuckGo Search |
| NER | spaCy xx_ent_wiki_sm + validation WUDD.ai |
| File watching | watchdog (détection temps réel des modifications du coffre) |
Modèle Ollama
ObsiRAG utilise un seul modèle pour toutes les opérations (chat, génération de questions, synapses) :
# Modèles recommandés
ollama pull qwen2.5:7b # chat + génération
ollama pull nomic-embed-text # embeddings (optionnel, sinon sentence-transformers en CPU)
Pour mesurer les performances sur votre machine :
python scripts/benchmark_ollama_chat20.py
Documentation technique
- docs/architecture.md — architecture actuelle, frontières entre modules, invariants et flux runtime
- docs/conversation-management.md — gestion des conversations, relances, note dominante, garde-fous
- docs/performances.md — mesures de performances et recommandations matérielles
- docs/performance-roadmap.md — feuille de route performance, gates Go/No-Go et KPIs
Statut
Projet actif — développé de façon créative et itérative avec Claude Code et GitHub Copilot.
Le dépôt est public. Contributions et idées bienvenues.
How to Install
- Download the ZIP or clone the repository
- Open the folder as a vault in Obsidian (File → Open Vault)
- Obsidian will prompt you to install required plugins
Stats
Stars
1
Forks
0
Last updated 1mo ago
Categories
Tags